42 KiB
بسم الله الرحمن الرحیم
آنچه در این مطلب به دنبال آن هستیم:
- مزایای Elasticsearch
- تفاوتهای Elasticsearch با sql
- ضرورت روی آوری به Elasticsearch
برای درک ضرورت استفاده از دیتابیس الاستیک سرچ لازم است ابتدا آشنایی اجمالی با انواع دیتابیس ها داشته باشید
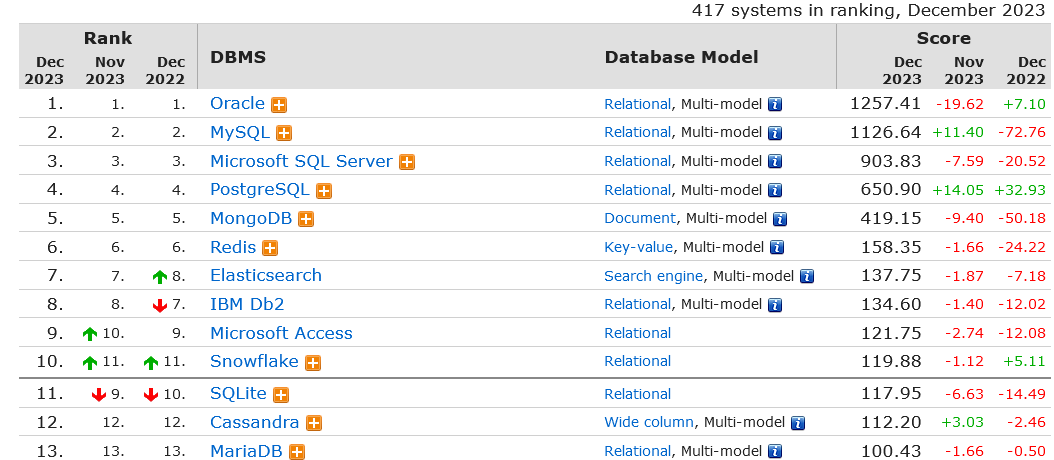
مقایسه انواع سیستم مدیریت پایگاه داده
در این مقاله ما 9 سیستم مدیریت پایگاه داده را که معروف ترین ها هستند برای مقایسه انتخاب کرده ایم که عبارت اند از MySQL ،MariaDB ،Oracle ،PostgreSQL ،MSSQL ،MongoDB ،Redis ،Cassandra و Elasticsearch. با تمرکز بر روی مزایای مربوط به هر پروژه یک مورد از این دیتابیس ها برای استفاده بهترین است و ما این مزایا را بررسی خواهیم کرد.
هنگامی که در حال توسعه یک اپلیکیشن هستید یکی از اولین سوالات این است چگونه داده های خود را ذخیره کنید. سیستم مدیریت پایگاه داده(DBMS) نرم افزاری است که با پایگاه داده، برنامه ها و رابط کاربری برای بدست آوردن اطلاعات و تجزیه و تحلیل آن ها ارتباط برقرار می کند. همچنین DBMS شامل ابزارهای کاربردی برای کنترل پایگاه داده است.
باید این نکته را بدانید که پایگاه های داده تنها بخشی از نگهداری و مدیریت داده ها هستند. در مقالات بعدی بیشتر در مورد این موضوعات صحبت خواهیم کرد.
دیتابیس های ارتباطی و غیر ارتباطی
به طور کلی دو مدل دیتابیس وجود دارد ارتباطی و غیر ارتباطی که همان سیستم های SQL و NO-SQL هستند. این سیستم ها از نظر بازیابی و توزیع و پردازش داده ها متفاوت هستند.
دیتابیس ارتباطی
از آنجایی که زبان Query هسته اصلی این سیستم ها را تشکیل می دهد(Structured Query Language) به این نوع سیستم ها SQL نیز گفته می شود. در این مدل پایگاه داده ها، اطلاعات به صورت جداول در سطرها و ستون ها و با ساختاری دقیق و و وابستگی های واضح ذخیره می شوند.
باتوجه به ساختار یکپارچه و سیستم ذخیره داده ها، پایگاه های داده SQL برای نگهداری و محافظت نیازی به تلاش مهندسی ندارند. آنها انتخاب خوبی برای توسعه و پشتیبانی از راه حل های نرم افزاری پیچیده هستند، جایی که هرگونه تعامل پیامدهای مختلفی را بر عهده دارد. یکی از اصول اولیه SQL مطابقت با ACID است. (مثلا اگر در زمینه تجارت الکترونیک و برنامه های مالی را توسعه می دهید سازگاری با ACID یک گزینه ترجیحی است.)
با این حال موضوع مقیاس پذیری می تواند در ساختمان های داده SQL یک چالش باشد. مقیاس بندی پایگاه داده SQL بین سرورهای متعدد(مقیاس بندی افقی) به مهندسی بیشتری نیاز دارد. در عوض پایگاه های داده SQL معمولا به صورت عمودی، یعنی با افزودن قدرت محاسباتی بیشتر به سرور، مقیاس بندی می شوند. در این مقاله ما چندین پایگاه داده SQL را مورد بررسی قرار می دهیم:
- MySQL
- MariaDB
- Oracle
- PostgreSQL
- MSSQL
دیتابیس غیرارتباطی
از آنجایی که این مدل ساختمان های داده محدود به ساختار جدول نیستند، NoSQL نامیده می شوند. این نوع سیستم مدیریت پایگاه داده به صورت سندگرا در نظر گرفته می شود. داده های بدون ساختار مانند مقالات، عکس ها، فیلم ها و موارد دیگر در یک سند جمع آوری می شوند. جست و جو کردن در داده ها ساده است اما مانند یک پایگاه داده SQL همیشه در ردیف ها و ستون ها ذخیره نمی شوند.
پایگاه های داده NoSQL معمولا با افزودن سرورها به صورت افقی مقیاس بندی می شوند. از آنجایی که پایگاه داده های NoSQL امکان رزرو انواع مختلف داده ها را با یکدیگر و مقیاس بندی آنها با رشد در سرورهای متعدد فراهم می کند، محبوبیت آنها روز به روز در حال افزایش است. NoSQL نیازی به آماده سازی قبل از استقرار ندارد و بروزرسانی سریع و بدون تاخیر در ساختار داده را آسان تر می کند.
در این مقاله ساختمان های داده NoSQL زیر را بررسی خواهیم کرد:
- MongoDB
- Redis
- Cassandra
- Elasticsearch
در ادامه نگاه عمیق تری به اینکه رایج ترین سیستم های پایگاه داده در SQL و NoSQL کدام هستند؟ و مزایا و معایت اصلی آنها چیست و چگونه باید در پروژه ها استفاده شوند؟ خواهیم داشت.
- مقایسه انواع سیستم مدیریت پایگاه داده
- مقایسه ساختمان های داده
- پایگاه داده MySQL
این نوع یکی از مشهورترین سیستم پایگاه داده ارتباطی است. MySQL در حال حاضر متعلق به شرکت اوراکل می باشد. امروزه MySQL پایه نرم افزار کاربردی LAMP می باشد. این نوع سیستم با توجه به ارتباطی که با زبان های C++/C دارد به خوبی با سیستم عامل های لینوکس، ویندوز و مک و بقیه سیستم عامل ها کار می کند. در ادامه مزایای MySQL را خواهیم دید.
از جمله مزایای دیتابیس MySQL میتوان به موارد زیر اشاره کرد:
- نصب رایگان: نسخه MySQL Community برای دانلود رایگان است و همچنین مجموعه ای اساسی از ابزارها برای استفاده غیر تجاری به همراه دارد. این نسخه گزینه خوبی برای شروع است. البته نسخه های غیر رایگان دیگری مانند Enterprise یا Cluster با عملکرد غنی تر وجود دارد. به هر حال اگر پروژه شما توانایی پرداخت هزینه برای این ساختمان داده را ندارد می توانید از نسخه رایگان استفاده کنید.
- توسعه بسیار ساده: ساختار و سبک MySQL بسیار ساده است. حتی توسعه دهندگان این ساختمان داده را با زبانی شبیه زبان انسان می دانند. از آنجایی که این ساختمان داده همزمان با زبان برنامه نویسی مانند PHP استفاده می شوند و دارای منحنی یادگیری ملایم هست. نیازی به یک توسعه دهنده ماهر برای مدیریت پایگاه داده خود نخواهید داشت و همچنین استفاده از آن بسیار ساده است. به عنوان مثال اکثر دستورات را می توان در خط فرمان اجرا کرد و مراحل توسعه را کاهش داد.
- سازگاری با فضای ابری: MySQL از نظر ماهیت تجاری در اصل برای وب توسعه یافته است و توسط محبوب ترین ارايه دهندگان فضای ابری پشتیبانی می شود. در پلتفرم های برجسته ای مانند آمازون و مایکروسافت در دسترس است و این امر MySQL را جذاب می کند و همچنین به مشاغلی که از آن استفاده می کنند فضای زیادی برای رشد می دهد.
همچنین این پایگاه داده برخی معایب نیز دارد که عبارتند از:
- چالش های مقیاس پذیری: پایگاه داده های MySQL مقیاس پذیری کمی دارند. در واقع اصلا برای مقیاس پذیری ساخته نشده اند. اگر چه شما می توانید این مدل پایگاه داده ها را مقیاس بندی کنید اما نسبت به بقیه پایگاه داده ها مشکلات بیشتری را به همراه خواهند داشت. بنابراین اگر پیش بینی می کنید روزی پروژه شما نیاز به پایگاه داده بزرگتری دارد بهتر است از همین ابتدا گزینه دیگری را انتخاب کنید.
- پیروی محدود از استاندارد های SQL: زبان SQL استانداردهای خاصی دارد. ساختمان داده MySQL به صورت کامل از این استانداردها پیروی نمی کند. یعنی MySQL هیچ پشتیبانی از برخی ویژگی های استاندارد SQL ارایه نمی دهد. از سوی دیگر حتی می توان گفت این پایگاه داده دارای برخی ویژگی های متمایز نسبت به زبان SQL است. این موضوع برای برنامه ها و پروژه های کوچک مشکلی ندارد اما اگر قرار به استفاده های بزرگ و توسعه داده ها باید ممکن است برای شما مشکل ساز شود.
- موارد استفاده: اگر داده های کمی برای پردازش دارید انتخاب پایگاه داده MySQL انتخاب خوبی برای شما خواهد بود. به عنوان مثال برای ساخت یک فروشگاه اینترنتی کوچک و محلی این پایگاه داده می تواند بسیار مفید باشد.
دیتابیس MariaDB
این پایگاه داده یک شاخه منبع باز از پایگاه داده MySQL است که پشتیبانی تجاری دارد. این پایگاه داده تحت مجوز GNU فعالیت می کند و دارای دستورات، API ها و کتابخانه های مشابه MySQL است.
از جمله مزایای دیتابیس MariaDB میتوان به موارد زیر اشاره کرد:
- رمزنگاری قوی: اوپن سورس بودن به معنای ناامن بودن نیست. این پایگاه داده علاوه بر امنیت داخلی و بررسی رمز عبور، ویژگی هایی مانند احراز هویت PAM، Kerberos و LDAP و نقش های کاربری را ارایه می دهد. این پایگاه داده یک لایه محافظ رمزنگاری شده قوی برای داده ها ایجاد می کند. علاوه بر همه این ها این پایگاه داده بروزرسانی های امنیتی زیادی منتشر می کند.
- عملکرد بالا: اگر چه MariaDB از موتور MySQL استفاده می کند اما از نظر عملکرد بسیار پیشرفت کرده است. ویژگی های بهینه سازی گسترده، مدیریت Thread pool و پردازش داده ها را بهبود می بخشد. بنابراین هنگامی که جداول از سیستم مدیریت داده ها حذف می شوند سیستم عامل بلافاصله به فضای آزاد دسترسی پیدا می کند و شکاف ها را پر می کند. علاوه بر آن سیستم مدیریت پایگاه داده آمار جدول را با استفاده از موتور خود در دسترس شما قرار می دهد و با کمک این ویژگی جست و جو در میان داده ها ساده خواهد شد و بهینه سازی داده ها نیز راحتتر می شود.
جامعه توسعه دهندگان این سیستم مدیریت پایگاه داده هنوز در حال گسترش است. از آنجایی که از زمان تاسیس و ساخت این سیستم زمان زیادی نمیگذرد تعداد متخصصان آن کمتر از بقیه سیستم های مدیریت پایگاه داده می باشد.
از جمله معایب آن می تواند موارد زیر باشد:
- اختلاف زیاد با MySQL: اگرچه تیم MariaDB سعی می کند به صورت مداوم خود را به طور مداوم با کدهای پایگاه داده MySQL هماهنگ کند اما هنوز هم اختلافات و شکاف های زیادی بین این دو سیستم مدیریت پایگاه داده وجود دارد. این موضوع باعث ایجاد مشکلاتی هنگام مهاجرت از MariaDB به MySQL می شود.
- موارد استفاده: از آنجایی که این سیستم مدیریت داده ها مانند MySQL است می توان از آن برای کار با برنامه های مبتنی بر وب استفاده کرد. علاوه بر این ها ذخیره سازی و بهینه سازی داده ها و مقیاس پذیری بهبود یافته است.
ضرورت استفاده از الاستیک سرچ:
به طور خلاصه آنچه که از معایب دیتابیس های ارتباطی گفته شده در حقیقت همان علت و ضرورت استفاده از دیتابیس های غیر ارتباطی نظیر الاستیک سرچ است. در ادامه با این نوع دیتابیس بیشتر آشنا خواهید شد.
مقایسهی دیتابیسهای SQL با NoSQL
تا اینجا با دیتابیسهای رابطهای آشنا شدیم. پیش از مقایسهی این نوع دیتابیسها با دیتابیسهای NoSQL به بررسی مفهوم دیتابیسهای NoSQL خواهیم پرداخت. دیتابیسهای NoSQL
این نوع دیتابیسها همانطور که از نامشان پیداست به مفهوم دیتابیسهای غیر SQL یا غیر رابطهای اشاره میکنند؛ یعنی دادهها را با فرمتی غیر از فرمت دیتابیسهای رابطهای ذخیره میکنند. اما منظور از این فرمتها چیست؟
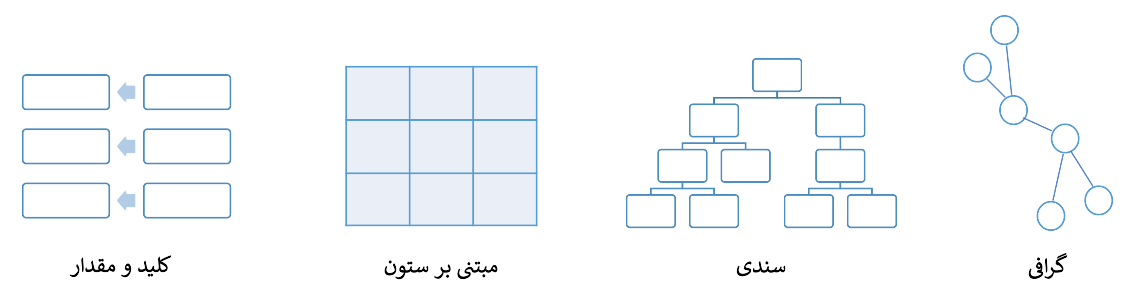 NoSQL
NoSQL
همانطور که در تصویر مشاهده میکنید، دیتابیسهای NoSQL به چهار دستهی کلی زیر تقسیمبندی میشوند:
- دیتابیسهای کلید و مقدار (Key-Value)
- دیتابیسهای ستونی (Column-Oriented)
- دیتابیسهای سندی (Document)
- دیتابیسهای گرافی (Graph)
دیتابیسهای کلید و مقدار
ایدهی اصلی این نوع دیتابیسها، جدولهای هش (Hash Tables) هستند که یک کلید منحصربهفرد را به یک مقدار وصل میکنند. از معروفترین این نوع دیتابیسها میتوان Redis را نام برد. برای درک بهتر این نوع دیتابیس، به مثال زیر دقت کنید:

در مثال بالا، کلید id است و مقدار 123. دیتابیسهای سندی
این دیتابیسها را میتوان نسل بعدی دیتابیسهای کلید و مقدار دانست. این دیتابیسها اجازه میدهند تا مقدار تودرتو برای هر کلید دلخواه قرار گیرد. در این دیتابیسها، دادهها در فرمتی ساختاریافته (مانند JSON یا XML) ذخیره میشوند. برای درک بهتر این قضیه، به مثال زیر توجه کنید:
 JSON
JSON
مثالی که مشاهده کردید، یک سند در اینگونه دیتابیسها است.
از معروفترین دیتابیسهای سندی، میتوان MongoDbوElasticsearch را نام برد. دیتابیسهای ستونی
این نوع دیتابیسها همانطور که از نامشان مشخص است، بهجای نگهداری دادهها در سطر، اینکار را در ستونها انجام میدهند، برای درک بهتر این قضیه به مثال زیر توجه کنید:
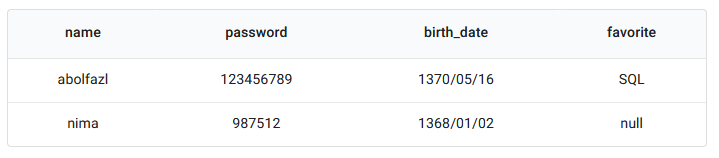
جدول بالا، جدولی در یک دیتابیس رابطهای است. جداول مبتنی بر ردیف هستند. همین جدول در دیتابیسهای مبتنی بر ستون بهصورت زیر است. در دیتابیسهای ستونی، جداول دارای فضایی تحت عنوان keyspace هستند. در keyspace ، تمامی دادهها به شکل ستونهای مختلف ذخیره میشوند که با column family ها از یکدیگر جدا میشوند. شکل زیر، مثالی از یک column family است:
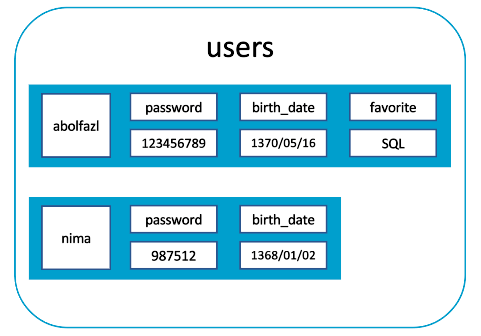
column
همانطور که در تصویر بالا مشاهده میکنید، یک column family به نام users وجود دارد که در آن ردیفهایی شامل دادهها در ستونهای مجزا قابل دسترسی هستند. در این حالت، abolfazl و nima اصطلاحاً کلید ردیفها هستند و باید منحصربهفرد باشند. مقدار favorite برای nima تعریف نشده است. این یکی از خواص دیتابیسهای ستونی است.
از معروفترین این نوع دیتابیسها میتوان Cassandra را نام برد. دیتابیسهای گرافی
این دیتابیسها با مفهوم گرافها شکل گرفتهاند و بهجای جداول، دادهها را در قالب گراف ذخیره میکنند. شکل زیر، نمایی را از این نوع دیتابیسها نمایش میدهد:
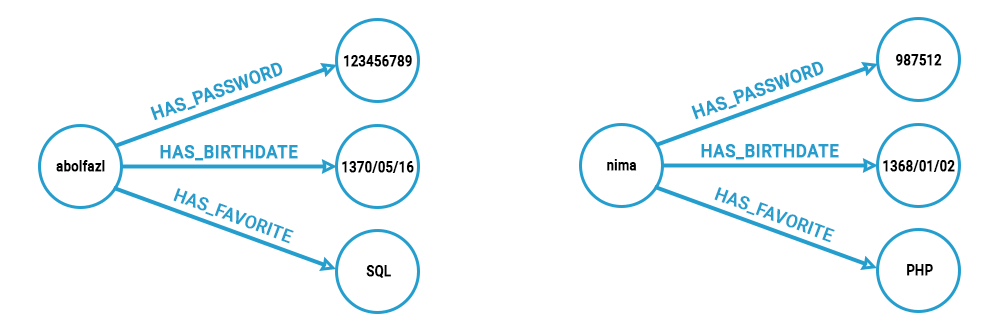
دیتابیس گرافی
از معروفترین این نوع دیتابیسها میتوان Neo4j را نام برد. تفاوت دیتابیسهای SQL و NoSQL
از مهمترین تفاوتهای دیتابیسهای SQL با NoSQL میتوان به نیازمندی دیتابیسهای SQL به یک ساختار مشخص برای نگهداری دادهها اشاره کرد. این نیاز در دیتابیسهای NoSQL وجود ندارد. همچنین دیتابیسهای SQL فقط مبتنی بر جداول هستند، اما دیتابیسهای NoSQL انواع مختلفی از نظر نحوهی ذخیرهسازی دادهها دارند.
دیتابیسهای SQL و NoSQL تفاوتهای بیشتری نیز دارند که در فصلهای بعدی به آنها میپردازیم. انتخاب دیتابیس متناسب با نیاز شما، مهارت و تجربهی کافی در کار با دیتابیسهای مختلف را میطلبد.

هر آنچه باید درباره الاستیک سرچ بدانید
همانطور که قبلاً هم در این سایت توضیح داده ام، الاستیک سرچ یکی از بهترین بانکهای اطلاعاتی سندمحور (منظور از سند، دادهای است که به شکل جیسان نمایش داده میشود) و همچنین جزء بهترین کتابخانه های جستجوی متن است که بر پایه کتابخانه معروف لوسین بنا شده است و علاوه بر سرعت بسیار بالا در پاسخگویی به انواع پرس و جوهای موردنیاز، توزیع شوندگی راحت در شبکه و سهولت بسیار زیاد در ورود داده، امروزه با افزودن داشبورد مدیریتی کیبانا و امکانات یادگیری ماشین و نیز ماژول هایی مانند LogStash و HeartBeat که به جمع آوری اطلاعات و لاگ ها از سرورهای مختلف می پردازد به یک گزینه بسیار ایده آل برای ذخیره و پردازش و مانیتورینگ داده های در جریان سیستم های عملیاتی معاصر تبدیل شده است.
اگر به لیست بانکهای اطلاعاتی برتر دنیا هم در سایت db-engines نگاهی بیندازید، این بانک را جزء ده بانک اطلاعاتی مطرح امروزین خواهید یافت.
الاستیک سرچ چیست و چه کاربردی دارد؟ چرا باید از Elasticsearch استفاده کنیم؟ در این مطلب از بلاگ ابر زس به این سوال پاسخ میدهیم و به مزایا و معایب الاستیک سرچ اشاره میکنیم.
با رشد و توسعه دنیا فناوری، هر روز حجم زیادی از دادهها تولید میشوند. انواع این دادهها به صورت متنی، عددی، ساختاری و یا بدون ساختار هستند. افراد برای درک این اطلاعات به ابزارهای تحلیلی نیار دارند، اینجاست که الاستیک سرچ وارد میشود.
Elasticsearch چیست؟
الاستیک سرچ یک موتور جستوجو، تحلیلگر دیتابیس، یک نوع ابزار ایندکس و راهکاری برای مدیریت کلانداده است که سرعت بلایی دارد و مقیاسپذیر است. بسته به اینکه تا چه میزان با این تکنولوژی آشنایی داشته باشید، این تعاریف میتواند شما را با Elasticsearch آشناتر کند یا حتی از نظرتان گیجکننده باشد. اما شاید برایتان سوال باشد که به زبان سادهتر، الاستیک سرچ چیست؟
Elasticsearch یک سیستم جستجو و تجزیهوتحلیل منبعباز بوده که روی آپاچی لوسن طراحی شده است. این سیستم جستجو در جاوا توسعهیافته و از زبانهای مختلف ازجمله PHP ،Python ،C و Ruby پشتیبانی میکند. به همین دلیل روی سیستمعاملهای مختلف اجرا میشود و میتواند حجم زیادی از دادهها را در کوتاهترین زمان ممکن جستجو و تجزیه و تحلیل کند.
الاستیک سرچ از ساختاری مبتنی بر اسناد بهجای جداول و الگوها استفاده میکند و دارای API REST گستردهای برای ذخیره و جستجوی دادهها است. میتوانید الاستیک سرچ را بهعنوان سروری در نظر بگیرید که قادر است درخواستهای JSON را پردازش کند و دادههای JSON را به شما برگرداند.
Elasticsearch چگونه کار میکند؟
در این قسمت از مقاله الاستیک سرچ چیست میخواهیم به بررسی نحوه عملکرد آن بپردازیم. الاستیک سرچ دادهها را در اسناد (documents) سازماندهی میکند. اسناد، شامل دادههایی تحت فرمت JSON هستند و تحت فایلهای JSON، موجودیتها (entities) نگهداری میشوند. اسناد، بر اساس مشخصاتشان به صورت فهرستهایی (indices) دستهبندی میشوند. الاستیک سرچ برای جستجوی کارآمد، از شاخصهای معکوس استفاده میکند که ساختارهایی از داده هستند که مکان کلمات در هر سند را مشخص میکنند.

الاستیک سرچ چیست؟
معماری توزیعشده الاستیک سرچ، این ابزار را قادر میسازد که جستجوها را سریع انجام دهد و برای تحلیل حجم عظیمی از دادهها، کارایی بالا و تقریبا بلادرنگی داشته باشد. الاستیک سرچ علاوه بر این که امکان رپلیکیشن (ایجاد کپیهایی از دادهها برای اطمینان بالاتر) را فراهم میکند به صورت مقیاسپذیری طراحی شده است. به این ترتیب با افزایش بار کاری، میتوان میزان منابع سرورها را افزایش داد. برای اینکه بهتر درک کنیم که Elasticsearch چیست، در ادامه به مفاهیم اساسی آن میپردازیم.
درک مفاهیم اساسی Elasticsearch
در این بخش از مقاله Elasticsearch چیست، بیایید نگاهی به مفاهیم اساسی داشته باشیم تا بیشتر با معماری آن آشنا شویم.
JVM
همانطور که در قسمت الاستیک سرچ چیست توضیح دادیم، این سیستم جستوجو به زبان جاوا نوشته شده است و از ماشین مجازی جاوا (JVM) استفاده میکند. JVM یک موتور اجرا است که بایت کد را در بسیاری از پلتفرمهای سیستمعامل اجرا میکند.
اسناد
سند، واحد اصلی و اساسی موجودیت اطلاعات در الاستیک سرچ است و در قالب JSON (مخفف JavaScript Object Notation) نمایش داده میشود. اسناد را میتوان ذخیره و ایندکس کرد. یک ایندکس دارای یک یا چند سند و یک سند دارای یک یا چند فیلد است. جستجو فقط در بین فیلدهای ایندکس شده امکانپذیر است و بازیابی محتوای اصلی فیلد فقط در فیلدهایی که بهعنوان stored در Mapping تعریف شدهاند امکانپذیر است.
فهرست (Indice)
Indice یا شاخصها، به مفهوم فهرست یا ایندکسها هستند. ایندکس به مجموعهای از اسناد گفته میشود که دارای ساختار و ویژگی مشابهی هستند و برای ذخیره و خواندن اسناد از آن استفاده میشود. در واقع ایندکس معادل یک پایگاهداده در RDBMS (سیستم مدیریت پایگاهداده رابطهای) است. هر Index با یک نام منحصربهفرد شناسایی میشود که تمامی حروف آن کوچک است و زمانی که عمل جستجو، بهروزرسانی یا حذف را انجام میدهید از آن استفاده میکنید.
استفاده از ایندکس معکوس بسیار شبیه جستجوی صفحه کتابی است که حاوی یک کلمه کلیدی خاص است و بهجای اسکن صفحات از ابتدا تا انتها، باید فهرست کلمات کلیدی درج شده در انتهای کتاب را اسکن کنید. این ایندکس معکوس، Elasticsearch را قادر میسازد تا دادهها را بهسرعت و کارآمد بازیابی کند.
شارد (Shard)
شارد در الاستیک سرچ چیست و چه کاربردی دارد؟ shard کوچکترین موجودیت در الاستیک سرچ است. Elasticsearch قابلیتی را فراهم میکند که با کمک آن ایندکسها به اجزای کوچکتری به نام شارد تقسیم میشوند. هر شارد یک ایندکس مستقل و با کارایی کامل است که میتواند در هر نود داخل هر کلاستر، میزبانی شود. در الاستیک سرچ دو نوع shard وجود دارد:
- primary shards: شاردهای واقعی که دادهها را نگه میدارند.
- replica shards: از شاردهای اصلی کپی شدهاند.
گره (Node)
گره یک سرور است که جزئی از یک کلاستر محسوب میشود. یک نود، دادهها را ذخیره کرده و در فرایند فهرستبندی و جستجوی کلاستر مشارکت میکند.
نودهای الاستیک سرچ میتوانند به ۳ روش مختلف پیکربندی شوند:
- نود مَستر: که کلاستر الاستیک سرچ را کنترل میکند و مسئولیت تمامی قابلیتهای کلاستر از جمله ایجاد یا حذف یک ایندکس و نیز افزودن یا حذف نودها را به عهده دارد.
- نود دیتا: دادهها را نگهداری کرده و عملیاتی مرتبط با داده از جمله جستجو و ترکیب آنها را انجام میدهد.
- نود کلاینت: درخواستهای کلاستر را به سمت نود مستر ارسال میکند و علاوه بر این درخواستهای مرتبط با دیتا را به نودهای دیتا میفرستد.
خوشه یا کلاستر (Cluster)
یک کلاستر از یک یا چند گره تشکیل میشود که به هم متصل شدهاند. قابلیتهایی که به یک کلاستر Elasticsearch قدرت میبخشند، شامل توزیع تسکها، جستجو و ایندکس شدن در تمامی نودهای یک کلاستر هستند.
رپلیکا (Replica)
سوالی که ممکن است برای خیلی از کاربران ایجاد شود این است که رپلیکا در الاستیک سرچ چیست؟ رپلیکا مکانیسمی است که Elasticsearch برای رسیدگی به خرابیهایی مانند آفلاین شدن گره بدون ازدستدادن دادهها استفاده میکند. علاوه بر این، رپلیکاها کمک میکنند ظرفیت سرویسدهی برای جستجو یا بازیابی یک سند، افزایش یابد.
به زبان سادهتر باید اینگونه توضیح داد که هر سند در هر ایندکس، متعلق به یک شارد اصلی است. رپلیکا، یک کپی از شارد اصلی محسوب میشود که میتواند مشابه شارد اصلی برای جستجو مورد استفاده قرار گیرد یا هنگامی که شارد اصلی با مشکل مواجه شد، جای آن را بگیرد.
بخشها (Segments)
مفهوم سگمنت در Elasticsearch یک مفهوم در سطح لوسن است که نشاندهنده تکههای یک شارد هستند. هر ایندکس لوسن حاوی یک یا چند Segments است. الاستیک سرچ گزینههایی را برای مدیریت اندازههای سگمنت و نحوه پیکربندی ارائه میکند که بر عملکرد ایندکس سازی تأثیر خواهد گذاشت. مزایای الاستیک سرچ چیست؟
اکنون که با این موضوع آشنا شدیم که الاستیک سرچ چیست، در این بخش به بررسی مزایا و اهمیت استفاده از آن میپردازیم. در مقایسه با بیشتر پایگاههای داده NoSQL، این فناوری بیشتر روی قابلیتهای جستجو تمرکز دارد و مجهز به یک API قدرتمند HTTP RESTful است. این قابلیت به شما کمک میکند تا حجم زیادی از دادهها را در زمان کوتاهی جستجو و آنالیز کنید. مهمترین مزایای استفاده از الاستیک سرچ عبارتاند از:
عملکرد بالا
ماهیت توزیعشده Elasticsearch آن را قادر میسازد تا حجم زیادی از دادهها را بهصورت موازی پردازش کند و بهسرعت بهترین پاسخ را برای درخواستهای شما پیدا کند. در واقع الاستیک سرچ دادهها را بهصورت همزمان با Shard و Replica در چندین نود یا گره پردازش میکند. این امر باعث افزایش عملکرد و بازیابی اطلاعات میشود. همچنین پردازش موازی نودها به استفاده موثر از حافظه کمک میکند.
موتور جستجوی متن کامل
سیستمهای مدیریت پایگاهداده SQL سنتی، برای جستجوی متن کامل در بین حجم زیادی از دادهها طراحی نشدهاند. ازآنجاییکه Elasticsearch روی Lucene ساخته شده است، یکی از قدرتمندترین قابلیتهای جستجوی متن کامل را ارائه میدهد و با استفاده از آن میتوانید انواع جستجوها از ساختاریافته تا بدون ساختار و از جغرافیایی تا متریک را انجام دهید و ترکیب کنید.
ابزارها و پلاگینها
الاستیک سرچ با کیبانا به یک ابزار تجسم و گزارش محبوب و یکپارچه تبدیل شدهاند. همچنین ادغام با Beats و Logstash را ارائه میدهد و به شما کمک میکند تا دادههای منبع را بهراحتی تبدیل کرده و آنها را در کلاستر Elasticsearch خود بارگذاری کنید.
عملیات نزدیک به ریل تایم
عملیات خواندن یا نوشتن دادهها در Elasticsearch، معمولاً کمتر از یک ثانیه طول میکشد. این امر به شما امکان میدهد از این سیستم جستجو برای مواردی مانند نظارت بر برنامه و تشخیص ناهنجاری استفاده کنید.
مقیاسپذیری
از ویژگیهای مهم الاستیک سرچ، مقیاسپذیری است. معماری Elasticsearch این امکان را فراهم میکند تا با افزایش حجم دادهها، همچنان عملکرد با کیفیت خود را حفظ کند. الاستیک سرچ همچنین میتواند دادهها را به طور خودکار تکرار کند تا در صورت خرابی گره، از نابود شدن آنها جلوگیری کند.
سازگار با بسیاری از زبانها
الاستیک سرچ دارای کتابخانه برای بسیاری از زبانهای برنامهنویسی مانند جاوا، جاوا اسکریپت، PHP، روبی، پایتون، #C و… است. دردسترسبودن این کتابخانهها، ادغام با Elasticsearch را برای برنامهنویسان بسیار آسان میکند.
جامعه کاربران گسترده
در انجمن کاربران میتوانید تقریبا برای هر سوال خود، پاسخی پیدا کنید یا حتی سوالات جدید خود را بپرسید تا یک کاربر مشتاق، پاسخی به شما دهد.
استفاده از API
یکی از دلایل اصلی افزایش محبوبیت الاستیک سرچ، API آن است که با اسناد آموزشی متعددی نیز همراه شده است. دردسترسبودن API، این امکان را برای توسعهدهندگان فراهم میکند تا با آن یکپارچه شوند. تقریباً هر ارسالکننده گزارش یا کتابخانه ثبت گزارش، دارای ابزارهایی برای ارسال داده به Elasticsearch است. علاوه بر ابزارهای مختلفی که میتوانند دادهها را از طریق API به الاستیک سرچ وارد کنند، ابزارهایی مانند کیبانا و گرافانا نیز وجود دارند که هدف آنها کاوش، تجزیهوتحلیل و نمایش دادههای این موتور جستوجو است.
معایب الاستیک سرچ چیست؟
الاستیک سرچ علاوه بر مزایایی که ارائه میدهد، معایبی نیز دارد که در ادامه به برخی از مهمترین آنها اشاره میکنیم:
نیاز به منابع بالا
برای استفاده و بهرهوری کامل از الاستیک سرچ به سرورهایی با حافظه رم ۶۴ گیگابایت نیاز دارید. در غیر این صورت با مشکلات احتمالی روبرو خواهید شد. از طرف دیگر، سرعت انجام درخواستها در SDD نسبت به هارددیسک بیشتر است. از آنجایی که هزینه SDD بالاتر است، در نتیجه برای ایجاد این زیرساخت باید هزینه بیشتر را در نظر بگیرید.
مشکل split-brain
از دیگر معایب الاستیک سرچ مشکل split-brain است. این مشکل زمانی به وجود میآید که سرورها بدون مشکل، مشغول به کار هستند اما ارتباط بین آنها قطع میشود. در نتیجه هر کدام از آنها خود را تنها در یک کلاستر میبینند و خود را به عنوان مَستر انتخاب میکنند. در چنین شرایطی، کلاستر با دو مستر روبرو میشود.
مشکل چندزبانی
برای مدیریت درخواستها و پاسخها، Elasticsearch تنها از فرمت JSON استفاده میکند، در حالیکه سیستمهای دیگر از فرمتهایی مانند CSV و XML نیز پشتیبانی میکنند.
فرایند یادگیری پیچیده
الاستیک سرچ قابلیتهای متنوعی را ارائه میکند اما مکانیزم کوئری پیچیدهای دارد؛ به ویژه اگر با مفاهیم دیتابیس یا SQL آشنایی نداشته باشید.
رایگان نبودن
الاستیک سرچ از سال ۲۰۲۱ به بعد دیگر رایگان نیست اما میتوان پلنهای مختلف آن را برای مدت محدود به صورت رایگان آزمایش کرد. موارد استفاده از Elasticsearch چیست؟
بهعنوان یک سیستم جستجو Elasticsearch بسیار مقیاسپذیر است و قابلیتهای جستجو در لحظه را ارائه میدهد. الاستیک سرچ به دلیل ماهیت همهکاره آن در مدیریت دادهها و جفتشدن با ابزارهای دیگر محبوب است. شرکتهایی مانند ویکیپدیا، نیویورکتایمز، گیتهاب، نتفلیکس، والمارت، ایبِی و فیسبوک همگی از این موتور جستوجو برای موارد مختلف استفاده میکنند.
مهمترین کاربردهای الاستیک سرچ
در ادامه به برخی از مهمترین کاربردهای الاستیک سرچ اشاره شده است:
جستجوی اپلیکیشن
برای اپلیکیشنهایی که به شدت به سرچها و گزارش های سنگین وابسته هستند، الاستیک سرچ از گزینههای مناسب است.
جستجوی وبسایت
وبسایتهایی که حاوی محتوای زیادی هستند میتوانند از این ابزار برای جستجوهای دقیق و کارآمد استفاده کنند.
جستجوهای سازمانی
Elasticsearch در سازمانها میتواند برای جستجوی اسناد، محصولات مبتنی بر تجارت الکترونیک، جستجوی بلاگ، افراد و … کاربرد داشته باشد.
ثبت و تحلیل لاگها
یکی از مرسومترین کاربردهای این ابزار، تحلیل لاگها تقریبا به صورت بلادرنگ است که میتواند بینشهای عملیاتی مهمی را در مورد گزارشها ارائه کند.
مانیتورینگ کانتینر و متریکهای زیرساختی
بسیاری از سازمانها از استک ELK برای تحلیل متریکهای متنوع از جمله پارامترهای مربوط به کارایی تجهیزات سرورها و نیز سرویسهای مبتنی بر کانتینر بهره میبرند.
تحلیلهای امنیتی
لاگهای دسترسی و سایر رویدادهایی که نگرانیهای امنیتی در مورد آنها مطرح است میتوانند به کمک استک ELK به صورت بلادرنگ و در لحظه، تحلیل شوند.
تحلیلهای تجاری
بسیاری از قابلیتهایی که با استک ELK همراه شدهاند، ابزارهایی عالی برای تحلیل سازمانها محسوب میشوند.
به این نکته توجه داشته باشید که الاستیک سرچ میتواند هم روی سرور اختصاصی و هم روی سرور ابری اجرا شود.
سخن پایانی
در این مقاله، به این موضوع پرداختیم که الاستیک سرچ چیست، چگونه کار میکند و چه مزایا، معایب و کاربردهایی دارد. به طور خلاصه Elasticsearch یک موتور جستجوی بسیار سریع و مقیاسپذیر است و در قلب اکوسیستم آن ابزارهای قرار دارد که با هم میتوانند برای مواردی از جمله جستجو، تجزیهوتحلیل و پردازش دادهها مورداستفاده قرار گیرند.
صلوات