# Multi^2OIE: Multilingual Open Information Extraction Based on Multi-Head Attention with BERT
> Source code for learning Multi^2OIE for (multilingual) open information extraction.
## Paper
[**Multi^2OIE: Multilingual Open Information Extraction Based on Multi-Head Attention with BERT**](https://arxiv.org/abs/2009.08128)
[Youngbin Ro](https://github.com/youngbin-ro), [Yukyung Lee](https://github.com/yukyunglee), and [Pilsung Kang](https://github.com/pilsung-kang)*
Accepted to Findings of ACL: EMNLP 2020. (*corresponding author)
## Overview
### What is Open Information Extraction (Open IE)?
[Niklaus et al. (2018)](https://www.aclweb.org/anthology/C18-1326/) describes Open IE as follows:
> Information extraction (IE) **turns the unstructured information expressed in natural language text into a structured representation** in the form of relational tuples consisting of a set of arguments and a phrase denoting a semantic relation between them: . (...) Unlike traditional IE methods, Open IE is **not limited to a small set of target relations** known in advance, but rather extracts all types of relations found in a text.
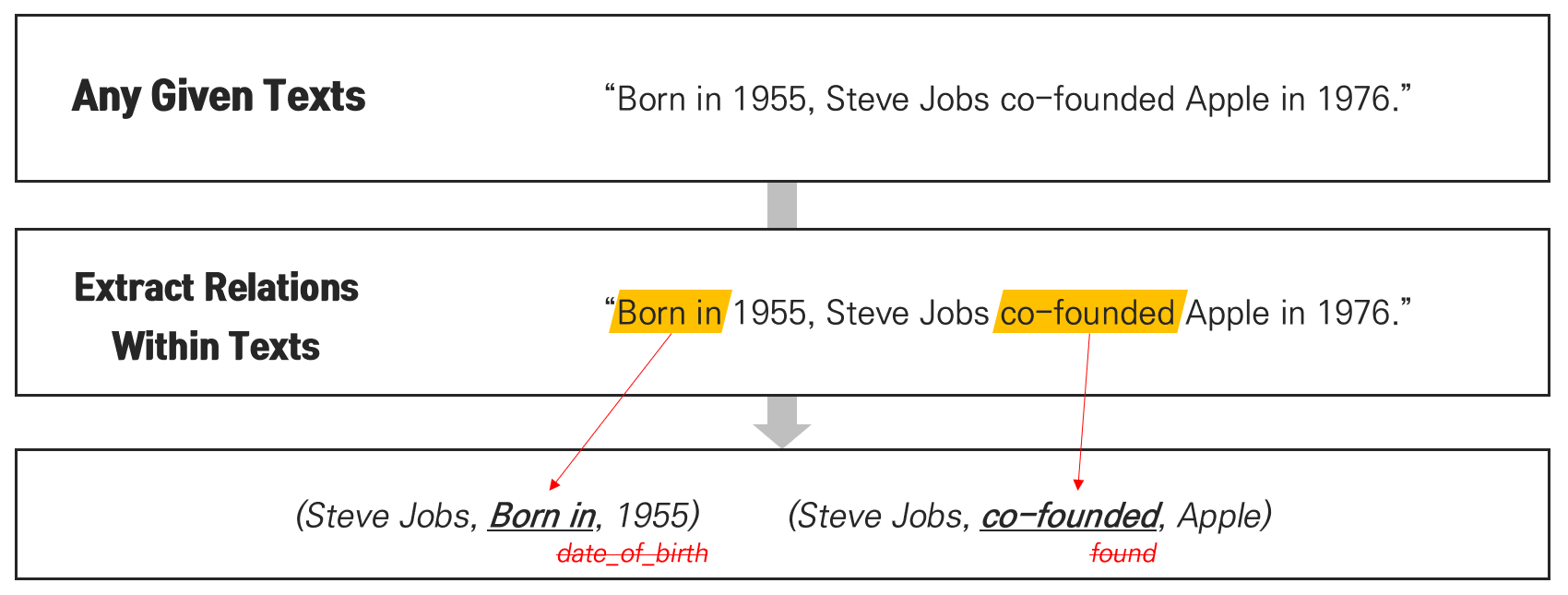
#### Note
- Systems adopting sequence generation scheme ([Cui et al., 2018](https://www.aclweb.org/anthology/P18-2065/); [Kolluru et al., 2020](https://www.aclweb.org/anthology/2020.acl-main.521/)) can extract (actually generate) relations outside of given texts.
- Multi^2OIE, however, is adopting sequence labeling scheme ([Stanovsky et al., 2018](https://www.aclweb.org/anthology/N18-1081/)) for computational efficiency and multilingual ability
### Our Approach
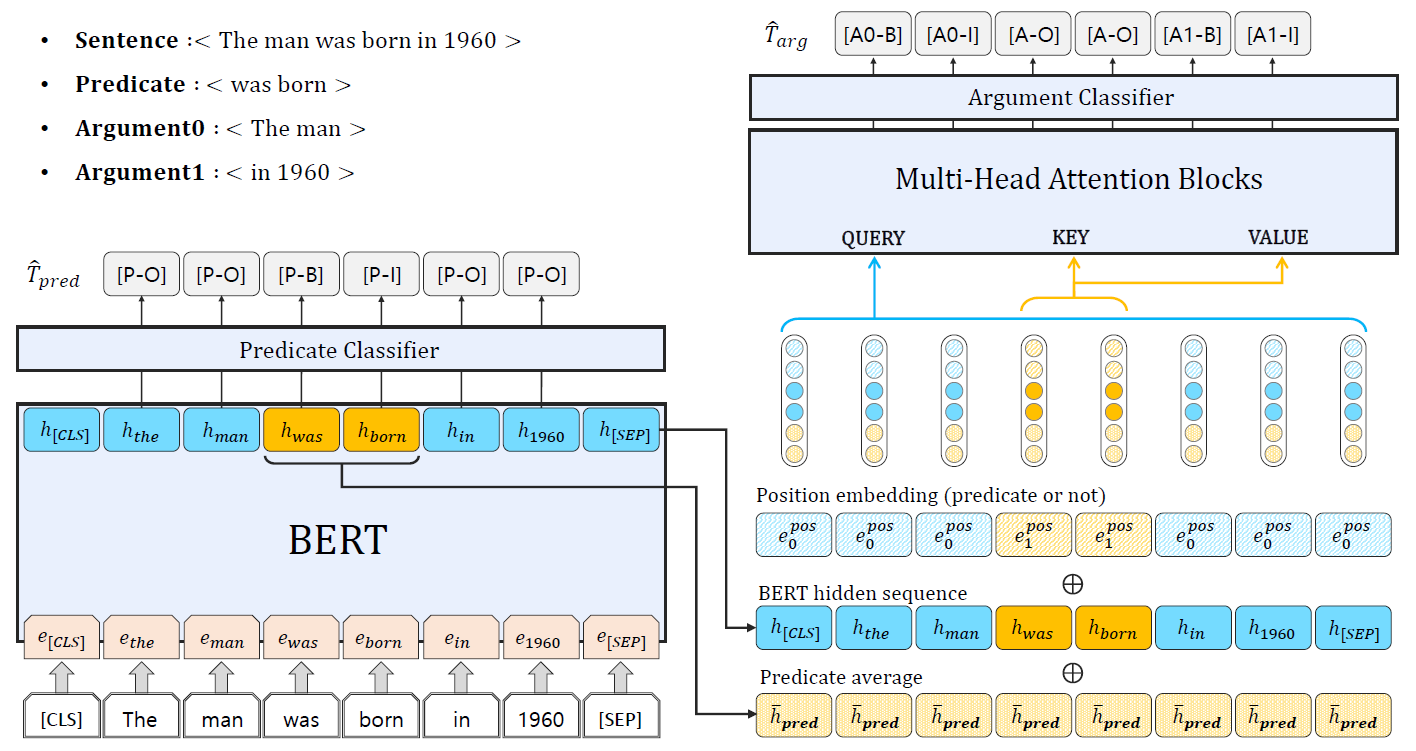
#### Step 1: Extract predicates (relations) from the input sentence using BERT
- Conduct token-level classification on the BERT output sequence
- Use BIO Tagging for representing arguments and predicates
#### Step 2: Extract arguments using multi-head attention blocks
- Concatenate BERT whole hidden sequence, average vector of hidden sequence at predicate position, and binary embedding vector indicating the token is included in predicate span.
- Apply multi-head attention operation over N times
- Query: whole hidden sequence
- Key-Value pairs: hidden states of predicate positions
- Conduct token-level classification on the multi-head attention output sequence
#### Multilingual Extraction
- Replace English BERT to Multilingual BERT
- Train the model only with English data
- Test the model in three difference languages (English, Spanish, and Portuguese) in zero-shot manner.
## Usage
### Prerequisites
- Python 3.7
- CUDA 10.0 or above
### Environmental Setup
#### Install
##### using 'conda' command,
~~~~
# this makes a new conda environment
conda env create -f environment.yml
conda activate multi2oie
~~~~
##### using 'pip' command,
~~~~
pip install -r requirements.txt
~~~~
#### NLTK setup
```
python -c "import nltk; nltk.download('stopwords')"
```
### Datasets
#### Dataset Released
- `openie4_train.pkl`: https://drive.google.com/file/d/1DrWj1CjLFIno-UBfLI3_uIratN4QY6Y3/view?usp=sharing
#### Do-it-yourself
Original data file (bootstrapped sample from OpenIE4; used in SpanOIE) can be downloaded from [here](https://drive.google.com/file/d/1AEfwbh3BQnsv2VM977cS4tEoldrayKB6/view).
Following download, put the downloaded data in './datasets' and use preprocess.py to convert the data into the format suitable for Multi^2OIE.
~~~~
cd utils
python preprocess.py \
--mode 'train' \
--data '../datasets/structured_data.json' \
--save_path '../datasets/openie4_train.pkl' \
--bert_config 'bert-base-cased' \
--max_len 64
~~~~
For multilingual training data, set **'bert_config'** as **'bert-base-multilingual-cased'**.
### Run the Code
#### Model Released
- English Model: https://drive.google.com/file/d/11BaLuGjMVVB16WHcyaHWLgL6dg0_9xHQ/view?usp=sharing
- Multilingual Model: https://drive.google.com/file/d/1lHQeetbacFOqvyPQ3ZzVUGPgn-zwTRA_/view?usp=sharing
We used TITAN RTX GPU for training, and the use of other GPU can make the final performance different.
##### for training,
~~~~
python main.py [--FLAGS]
~~~~
##### for testing,
~~~~
python test.py [--FLAGS]
~~~~
## Model Configurations
### # of Parameters
- Original BERT: 110M
- \+ Multi-Head Attention Blocks: 66M
### Hyper-parameters {& searching bounds}
- epochs: 1 {**1**, 2, 3}
- dropout rate for multi-head attention blocks: 0.2 {0.0, 0.1, **0.2**}
- dropout rate for argument classifier: 0.2 {0.0, 0.1, **0.2**, 0.3}
- batch size: 128 {64, **128**, 256, 512}
- learning rate: 3e-5 {2e-5, **3e-5**, 5e-5}
- number of multi-head attention heads: 8 {4, **8**}
- number of multi-head attention blocks: 4 {2, **4**, 8}
- position embedding dimension: 64 {**64**, 128, 256}
- gradient clipping norm: 1.0 (not tuned)
- learning rate warm-up steps: 10% of total steps (not tuned)
- for other unspecified parameters, the default values can be used.
## Expected Results
### Development set
#### OIE2016
- F1: 71.7
- AUC: 55.4
#### CaRB
- F1: 54.3
- AUC: 34.8
### Testing set
#### Re-OIE2016
- F1: 83.9
- AUC: 74.6
#### CaRB
- F1: 52.3
- AUC: 32.6
## References
- https://github.com/gabrielStanovsky/oie-benchmark
- https://github.com/dair-iitd/CaRB
- https://github.com/zhanjunlang/Span_OIE